Timothy - An Exercise in Applied AI
Published on: Jun 14, 2026Filed under: Technology
I skipped crew practice this weekend, partially because I have been pushing myself too hard recently and partially because most of my usual crewmates wouldn't be there. Instead I woke up and immediately started work on Timothy - my current side project and the consumer of most of my free time for the past four months.
On Saturday morning, Timothy gave me its first positive product experience so far.
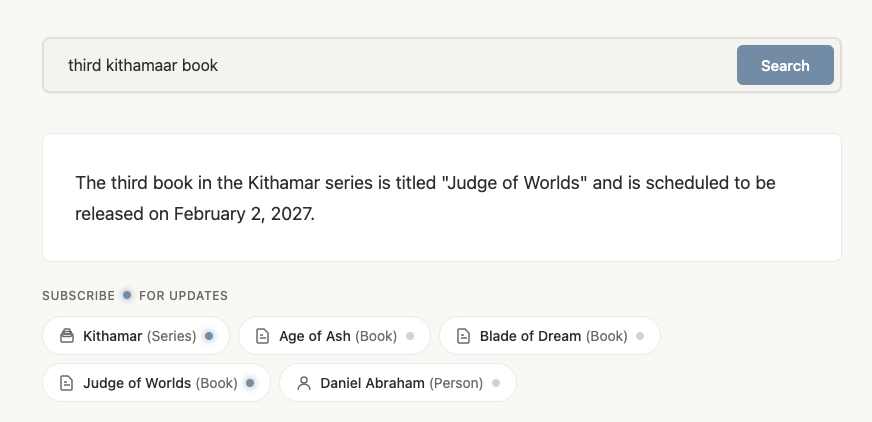
That simple screen cap is Timothy told me that a book I had been tracking finally had a release date. And it's deceptively complex. Timothy unpacked the query to understand it isa bout a series, an installment within that series, and then extracted known facts about the specific installment (such as the title and release date to render an answer back.
Timothy is a media agent. It's an AI system designed around understanding media (books to start, but eventually games, movies, music, and TV shows) not from a content standpoint, but from a relational stance.
Timothy's goal is to know everything about a book without knowing about what is in a book. Things like who wrote the book, what genre it belongs in, who published the book, and (critically) when the book is being released. And then to relate all of that data to other things in a giant web.
For years I've just kept a list of things I'm interested in and googled them on occasion. This is a great, big, overengineered means of not having to do that anymore. To offload the task of opening a document, searching a thing, noting changes, and recording them in that document.
But Timothy is also an excuse to build an applied AI system how I believe AI systems should be built, and though it uses LLMs at some points in the chain, Timothy is fundamentally different from what most people describe as AI in 2026.
Timothy Builds a Persistent World State
The first thing that separates Timothy from an LLM is that Timothy creates, updates, and reasons from a persistent world state. Though some have argued that LLMs maintain some rudimentary version of a world state through semantic patterns[1], that world state is mostly fixed at time of training and can only be modified as long as the context window is maintained. By any definition, that's not a world state. That's goldfish memory, and potentially more evidence of LLMs being stochastic parrots [+]I don't believe that LLMs have a world state. Nor do I believe they actually reason. All of the evidence I have seen is that LLMs merely produce probable tokens into trained shapes and that things like reasoning are merely tokens that look like thought to influence future probabilities. To borrow from Baudrillard, that's not real reasoning, that's hyperreasoning..
To understand Timothy's world state, it helps to understand the system.
A Timothy experience starts with a user's query. Timothy takes the query and assembles claims, it then reasons those claims into one or more facts, and persists those believed facts into a graphed world state. Timothy answers the query by reasoning from the world state, not from the claims.
From a product perspective, this means that every new query increases the size and shape of what Timothy believes about the world. Theoretically, every interaction makes Timothy smarter. Unlike most modern AI, Timothy will both admit when it doesn't know something and actually learn over time. More queries mean more facts mean a fuller world state.
Timothy is Proactive and Material
The next difference between Timothy and most modern AI systems is that it is proactive and material by design.
The way Timothy's world state is built is through the understanding of real-world things as entities. Stephen King is an entity. A Tale of Two Cities is an entity. Random House is an entity. And 1984 is two different entities - a book and a year.
Users are able to subscribe to entities, and subscriptions tell Timothy to keep gathering claims on the entity. When a user subscribes to Stephen King, Timothy will repeatedly search for new Stephen King-related claims. It will continue to evaluate these claims for facts that can be contributed to the world state. And if a new fact enters the world state that is materially relevant, that fact is communicated to the users who subscribed to the entity.
It's functionally autosearch with an added layer of intelligence. Instead of Timothy notifying users every time an old book is newly added to the world state, Timothy applies structured reasoning and only communicates updates that are meaningful [+]This is because companies have enshittified notifications to the point where I actively dislike them. And since this is my product, not annoying users is one of the core product tenets..
The proactive nature means that Timothy's world state updates itself to reflect the real world without needing expensive, lengthy, and environmentally damaging training cycles.
Timothy is Modular and Multi-Tooled
Finally, Timothy is more than a simple agent harness, more than just a series of prompts in a trench coat calling itself a product.
Rather, Timothy is a full web application architected in a stubbornly modular fashion, where each major job function (claim extraction, fact assertion, materiality filtering, etc.) is isolated and governed by a strict data contract.
This modularity means that I'm able to use the right tool for each functional job. This leaves Timothy looking more like a series of smart production lines and less like a single model that maintains an asymptotic relationship with intelligence [+]Yes, this is a sly statement that LLMs don't meet the definition of artificial intelligence and will never actually achieve AGI. That belief is based on two faulty logical leaps. The first is that language is intelligence — it's not. As my friend Abbie Byrum noted, "Language is a lossy information transmission mechanism." We store intelligence as information through language, not the other way around. Second, LLMs predict the next probable token, not the correct token. Whenever the correct token is improbable, LLMs will misalign with reality. This is why I'm frequently on the record as saying, "All outputs are hallucinations. Some hallucinations happen to be correct.".
Granted, Timothy does occasionally use LLMs, but only for what they're good at:
- Turning language into structured data
- Turning structured data into language
But I could argue [+]and I am, in fact, arguing that that's all LLMs should be used for.
Other functions in Timothy are handled with simple ML models, or rules, or even good ol' programming. If anything, this makes smoke testing easier and the whole system idempotent.
All of this has been built, though it's still firmly in what I call the 'Crawl' stage. I'm hoping to get Timothy into a deployable shape by the end of the month. And I'm quite ready to not have to google for upcoming book news anymore. Timothy can just give me the facts.